梦里不知身是客Jedis使用中的几个概念 2016-04-17
转载请注明出处
作者:晓渡
文章地址:https://greatestrabit.github.io/2016/04/17/firstjedis/
这两天随便玩了一下Jedis,初步了解了一下其中的几个概念,记录一下.
1.数据组织方式
1.数据库
Redis中默认设置了16个数据库,编号为0~15,可以通过修改配置文件来修改数据库个数.可以使用select(databaseNo)方法来选择使用的数据库.
2.文件夹
Redis的Key中使用冒号作为分隔符,在RedisDesktopManager中查看可以看到分级的文件夹.需要注意的是,这种方式只有在客户端中查看才能看到分级效果,实际的Key并没有变化.
3.HSET
HSET的存储方式可以在一个Key中保存一组Key-Value.
以上三种方式组合,可以将数据逐层分级,方便存储和查找.下面是一个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20Jedis jedis = new Jedis("192.168.20.252");
jedis.select(1);
jedis.hset("movie:war:Fury", "score", "7.6");
jedis.hset("movie:war:Fury", "website", "http://www.imdb.com/title/tt2713180");
jedis.hset("movie:war:Fury", "Director", "David Ayer");
jedis.hset("movie:war:Fury", "Writer", "David Ayer");
jedis.hset("movie:war:BlackHawkDown", "score", "7.7");
jedis.hset("movie:war:BlackHawkDown", "website", "http://www.imdb.com/title/tt0265086");
jedis.hset("movie:war:BlackHawkDown", "Director", "Ridley Scott");
jedis.hset("movie:war:BlackHawkDown", "Writer", "Mark Bowden");
jedis.hset("movie:action:TheRundown", "score", "6.7");
jedis.hset("movie:action:TheRundown", "website", "http://www.imdb.com/title/tt0327850");
jedis.hset("movie:action:TheRundown", "Director", "Peter Berg");
jedis.hset("movie:action:TheRundown", "Writer", "R.J. Stewart");
jedis.hset("music:pop:FuckinPerfect", "length", "3:33");
jedis.hset("music:pop:FuckinPerfect", "size", "8.5M");
存储后的效果如下: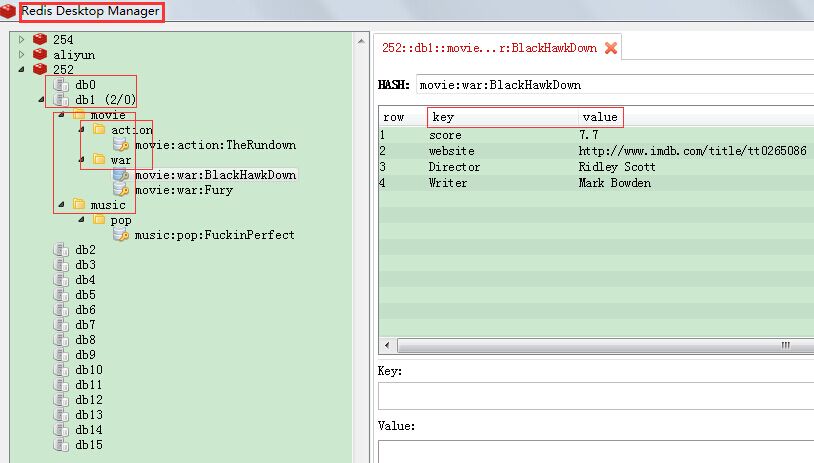
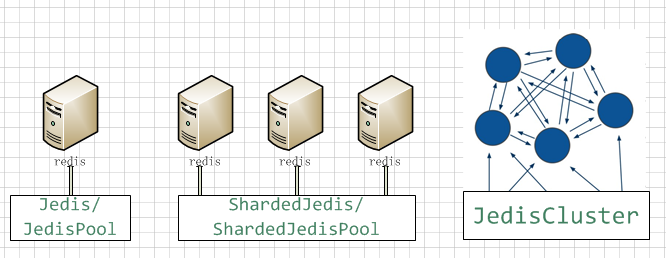
2.Jedis连接方式
使用Jedis连接Redis服务器有三种方式:Jedis/JedisPool,ShardedJedis/ShardedJedisPool,JedisCluster,分别对应了服务器的不同部署方式.
1.使用Jedis/JedisPool连接
这种方式针对单个Redis服务器建立连接,Jedis是单个连接,JedisPool即Jedis连接池,为了优化连接性能而生.
2.使用ShardedJedis/ShardedJedisPool连接
这种方式可以连接互不相通的一组Redis服务器.即Redis服务器因为数据量太大在数据上进行了水平拆分,但是服务器间并不通信,也没有副本备份.同样的道理,ShardedJedisPool是针对ShardedJedis单个连接所做的优化.
3.使用JedisCluster连接
使用这种方式时,默认Redis已经进行了集群处理,JedisCluster即针对整个集群的连接.
上述三种方式的对比如下: